At each step the agent reads an observation (task spec, files, code, command output, metrics), writes an action (edit files, run a command, submit for evaluation), and the sandbox returns results that feed the next step — a closed empirical loop under a fixed budget.
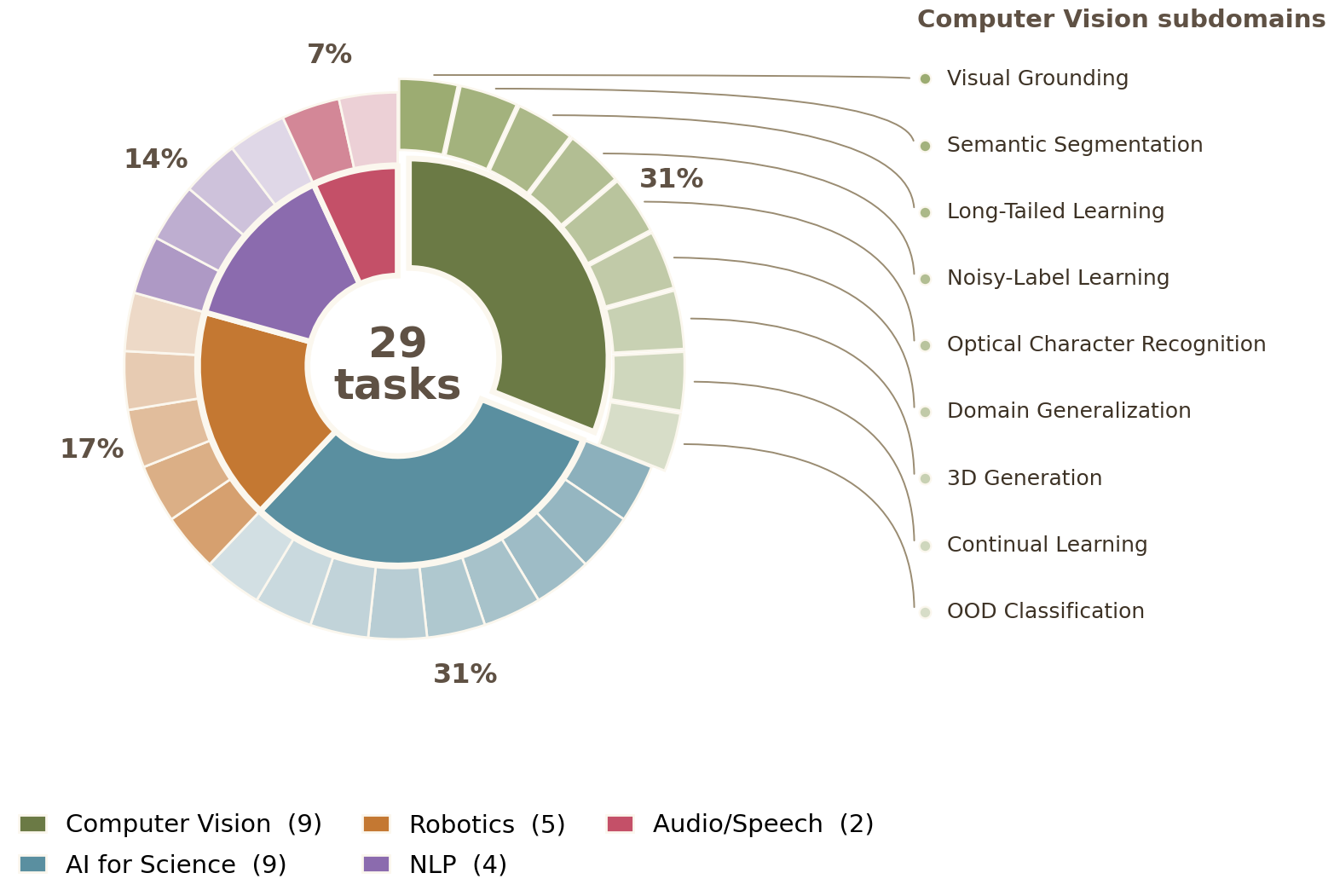
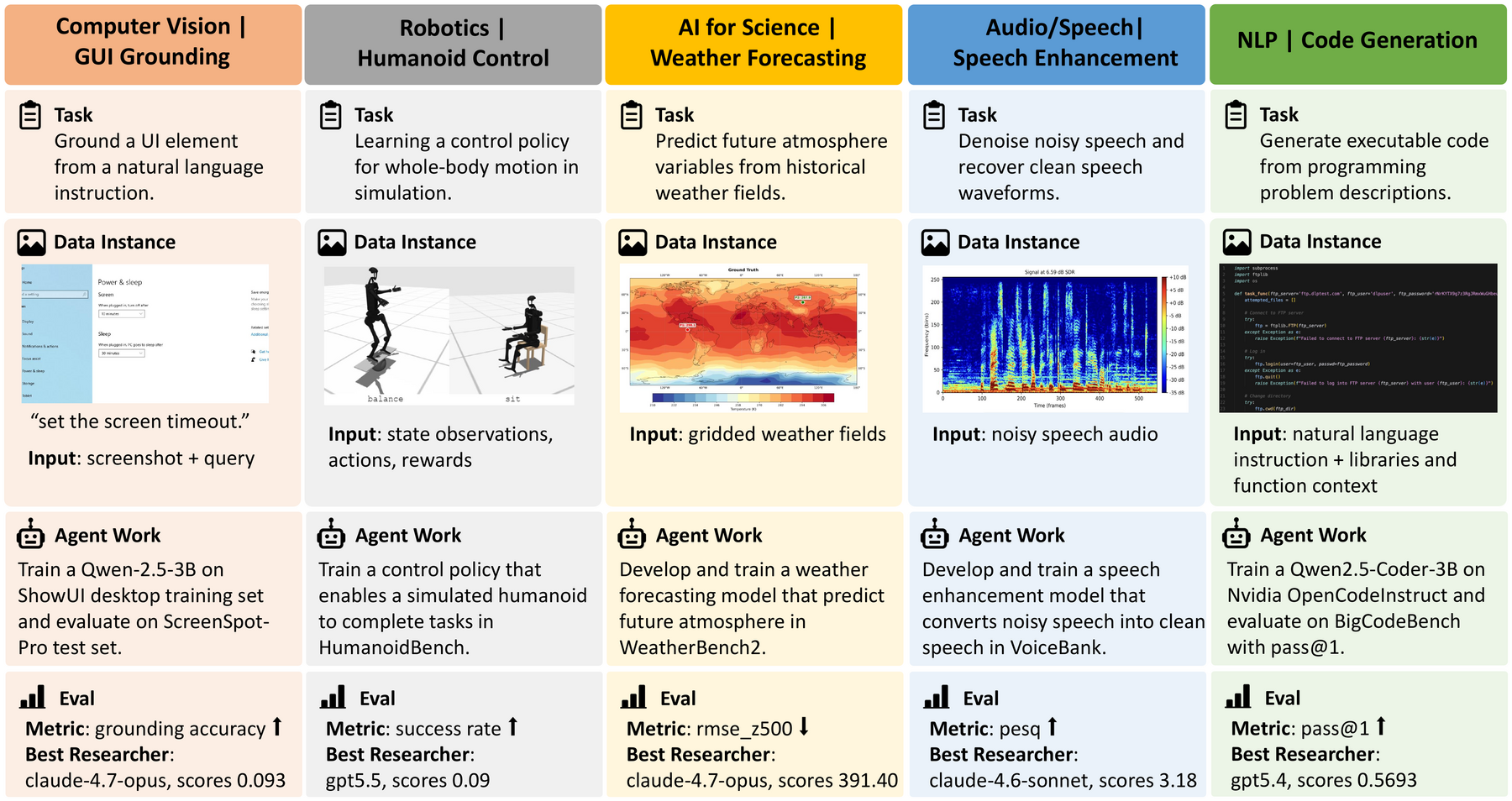
29 real-world ML tasks across five research domains. Each task ships with a description, a primary metric, a compute budget, and an automated evaluator.
Headline takeaways from agent–task episodes across frontier models.
Current frontier agents are useful research assistants — not yet reliable autonomous researchers.
-
01
Top agent reaches only / 100.
Even the strongest agent () leaves points still to be earned — far from doing research on its own.
-
02
Running the loop is easy; improving within it is hard.
8 of 11 agents reliably read the task, write code, run experiments, and read the results. The gap appears after that: even the strongest agent recovers less than a quarter of the remaining room to improve after its first valid result.
-
03
Most agents barely improve after their first try.
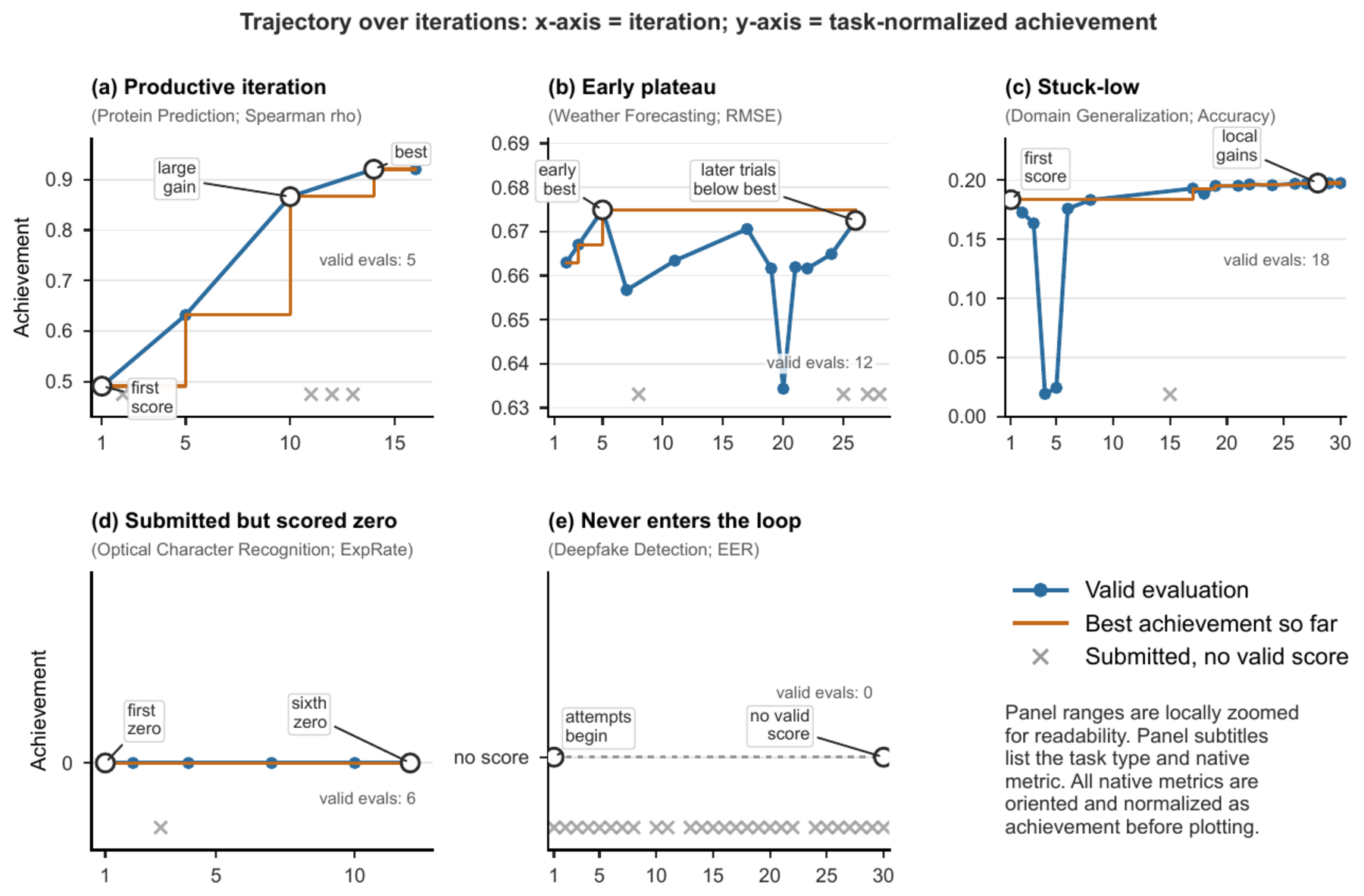
Across 301 valid agent–task attempts, the median improvement from first to best is only 3 percentage points of normalized achievement. 30% don't improve at all; 69% improve by less than 10 percentage points. The problem isn't that agents never see whether an idea worked — they fail to convert that signal into a better next decision.
-
04
More iterations don't help.
Whether an episode ends from the agent's own done signal, the 30-iteration cap, or wall-clock exhaustion, average improvement plateaus at the same ceiling. More tries alone don't unlock better research — high-gain iteration isn't yet the default behavior.
-
05
Agents keep tweaking the same thing.
In ~30% of episodes, when a result is poor the agent keeps editing the same layer of the solution — the hypothesis, the data pipeline, the modeling assumption, or the evaluation contract — instead of revising it. Productive trajectories are hypothesis-driven; the rest are continuation-driven. The paper calls this wrong-layer fixation.
Five representative trajectories connect the aggregate findings above to concrete agent-task episodes: one productive loop, and four ways feedback fails to become a better research decision.
Paper in preparation (2026). The BibTeX entry will be updated on release.